Richer Text Fields (Explainer)
- Authors
- @keithamus
- Created
- Last Updated
Introduction
<input> and <textarea> are the bread and butter of user interaction, but
their content is limited to plain content. In order to provide richer
experiences developers ultimately have two techniques at their disposal: to
“hack” inputs by surrounding or overlaying/underlaying elements which, aside
from the difficulty to implement, can be extremely fragile and error prone.
The other solution is to make the leap to using contenteditable which brings
its own set of problems, leading to an out-of-the box inaccessible experience
and requiring a large amount of remediation work to get to net-zero.
This proposal introduces a set of smaller functionality around <input>s and
<textarea>s that collectively aim to allow developers to build out richer
input controls for the web. They can be roughly broken down into four themes:
- Give developers the ability to extract range information from an
<input>or<textarea>. - In turn, allow developers to apply CSS Highlights to those ranges, to allow for parts of an inputs value to be styled.
- Provide “input masking” to allow for presentational characters to be added to inputs, improving usability for complex constrained inputs, for example dates, currencies, PINs, and so on.
- Provide an API for making “suggestions” within an input which users can accept or reject to aid in data entry.
While each of these is a discrete proposal for new APIs, and each has discrete use cases, the combination of these features unlock additional use cases and can allow developers to solve novel problems far more easily.
A note on contenteditable
Generally speaking, all of the above could be solved by utilising the
contenteditable attribute. However, contenteditable is very complex to
effectively utilise and has a litany of additional complexities to resolve,
in order to get an equivalent experience
(1,
2,
3),
and has various longstanding compatibility issues
(1,
2,
3,
4). While it’s possible to
resolve cross-browser issues, the fundamental design of contenteditable
requires a significant amount of work to migrate from traditional form fields.
This proposal (or set of proposals) aims to bridge the gap; extending existing
<input> & <textarea> elements functionality so that developers do not need
to reach for contenteditable (or other hacks) quite so often, in the hope
that the web retains a high degree of accessibility into the future.
Range Information
https://github.com/whatwg/html/issues/10614, https://github.com/w3c/csswg-drafts/issues/10346
Today it is possible to get Range information from nodes. The Range
interface specifies a region of text within a node, and can be used to drive
Selection and Highlights. It is not possible to use Range interfaces to
select part of an <input> or <textarea>s live value.
Why would we need Range information?
Range information is useful for two main reasons:
- Getting the bounding
DOMRectcan be useful to anchor popover or other decorative elements to the current selection, the caret, or a specified range. - Passing the
Rangeto the CSS highlight API could enable richer inputs without having to go to extreme lengths to style portions of an inputs value.
Problem Statement
Today, it is not possible to extract Range information from a <textarea>
or <input> value. Trying to do so will result in selecting the node
representing the initial value of the <textarea>, or nothing in the case of
<input> elements.
<textarea id="field">This is the textarea initial value</textarea>
<script>
const r = new Range()
r.setStart( field.children[0], 13 )
r.setEnd( field.children[0], 21 )
</script>
The above JavaScript will select the text node that represents the field’s initial value, but not the values current value.
How this is solved today
For developers that wish to extract such Range information for the current
value, they will need to duplicate the <textarea> element into a new node,
assign the .textContent to the field .value, and then extract range
information from that:
<textarea id="field">This is the textarea initial value</textarea>
<script>
const r = new Range()
const fakeField = document.createElement('div')
fakeField.textContent = field.value
const styles = getComputedStyle(field);
for (let i = 0; i < styles.length; i += 1) {
const name = styles[i];
fakeField.style[name] = styles[name];
}
field.insertAdjacentElement(fakeField, 'afterend')
r.setStart( fakeField.children[0], 13 )
r.setEnd( fakeField.children[0], 21 )
</script>
This will provide a Range interface that can provide the user some information,
such as the bounding DOMRect, but it is computationally expensive to clone the
element and all of its styles simply to get the DOMRect, and would need to be
re-done for any style changes (such as changing writing direction) and yet more
work is needed to manage selections correctly.
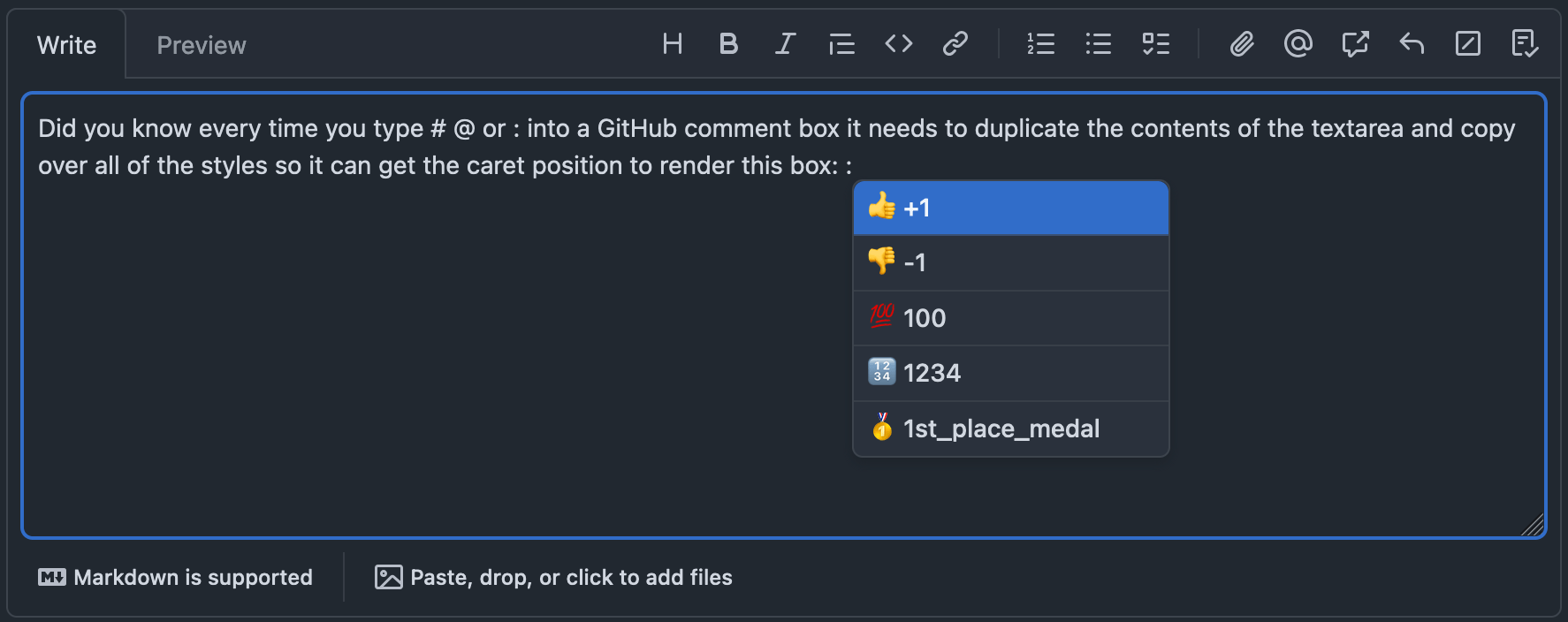
GitHub’s <text-expander-element> is a Custom Element built to handle this
specific use case, and powers the Emoji, Issue and At-Mention suggestions
inside comment fields. In order to do this, it uses an underlying library -
dom-input-range which uses
the above described technique of copying the textarea in order to extract
Rects.
How we’d like to solve this in the future
Here are two possible paths to solving this:
Expanding Range
Expanding the Range() interface’s .setStart() and .setEnd() to
select the live value of an <input> or <textarea> element.
This would transparently ensure that, when given a <textarea> or
<input>, setStart() would use the live value instead of the child
nodes (where applicable). This comes with compatibility risks, where
existing callsites that pass these values in may result in new selections
in surprising ways. Additionally, this opens a potential for composed
Ranges which select content adjacent to, as well as inside, the field -
which is potentially undesirable and not currently possible today.
Adding a new Range type
Adding a new InputRange() sub-class of Range(), the exclusive purpose
of which is to create ranges on <input> and <textarea> elements. The
.setStart() and .setEnd() methods would only allow <textarea> or
<input> as a Node, and would otherwise throw an Error.
This would increase the API surface area of the web platform, but on the
other hand it side-steps the issues around transparently extending Range.
The InputRange() interface offers a natural boundary layer between other
Range elements and avoids selection compositio issues for APIs where
Range can span multiple nodes. The CSS highlight API, for example, can
special case InputRange. Additionally, a separate interface can side-step
potential security issues, for example serialising with .toString() could
throw, the .surroundContents() function can be elided, and so on.
CSS Highlights on inputs
CSS highlights
are a new API to style text ranges in a given node, using the ::highlight
pseudo element. This same API would be very useful for also styling ranges
inside of an <input> or <textarea>.
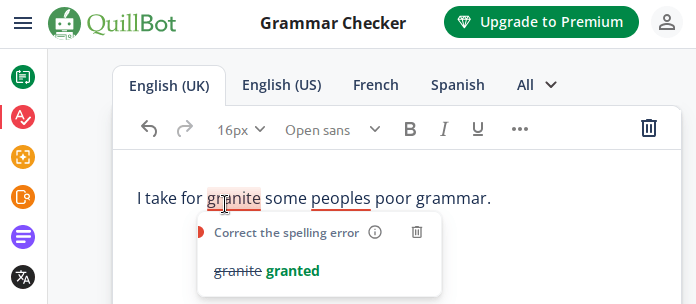
Why would we need CSS highlights in <input> or <textarea>?
Today, it is a common UI pattern to decorate regions of text within an input for example to suggest potential spelling or gramatical mistakes, syntax highlighting, or to highlight side-effectful regions of a message:

Problem Statement
Today, it is not possible to get Range information from input and textareas (see above) and therefore it is also not possible to supply ranges to the CSS highlights API. Unlocking the facility to provide CSS highlights to input ranges would make it much easier to create this kind of UI, which is otherwise very difficult to achieve.
How this is solved today
Aside from contenteditable it is possible to overlaying (or underlay) an input
with a <div>; tracking the user’s input, rendering a richer version into the
<div>. GitHub’s search bar does exactly this, setting the color &
background-color of the <input> to transparent which allows sighted
users to see the <div> that is sitting below. As the user inputs text,
the <div> sitting below is populated with a syntax-highlighted variant of
the input. This is tricky to get right and remains fragile; the source of many
bugs. Correctly tracking composition events, for example, can be challenging
(refer to this bug report during a private beta ship of this
feature).
Additionally there are myriad ways to break the effect, such as forced fonts,
text-zoom, or changing writing directions, which all need to be actively
mitigated:
How we’d like to solve this in the future
Extending the CSS.highlights API to accepting ranges from input elements (see
above proposal on InputRange) would solve this simply and effectively.
It would also be useful (though not necessary) to extend the CSS highlights API
to allow for styling the cursor, caret-color & outline properties in the
way that both ::spelling-error and ::grammar-error allow today.
Text automcomplete suggestions, aka “Ghost Text”
A common UI pattern is having “predictive” suggestions that provide the rest of
the word or sentence you’re typing. Often these can be contextually aware, for
example the predictive model can be programmed around (or trained on) data
within the product. Browsers have the facility to enter such predictions based
on the operating system and browser combination; for example Apple’s iOS 18 or
Microsoft Edge on Windows both offer this, which can be turned off using the
writingsuggestions attribute. However, often sites wish to provide their own
suggestions which may be more conextually relevant:
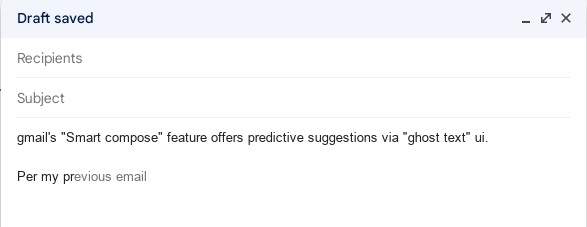
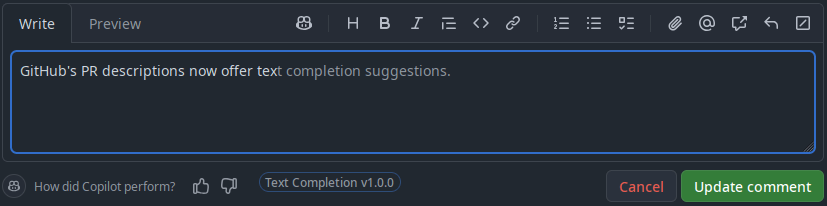
These “Ghost Text” suggestions are not only limited to predictive completions, but can also offer increased usability in aiding a users understanding about how autocomplete options may alter an input value:
Why would we need “Ghost Text” in the browser?
This is a common UI pattern and is likely to get more common with the proliferation of LLMs especially as their availability increases in the web platform with APIs such as WebNN or the Writing Assistance APIs.
It’s also a very difficult effect to achieve for multiline inputs, due to
the limitations of <textarea>.
How is this solved today?
Like the other solutions, its possible to cheat this effect by underlaying/
overlaying an element such as a <div> and copying over the content. Like
the others this comes with the usual problems of tracking styling (such as
writing direction), but there are other issues when it comes to multiline
input and setting a value:
- Textareas need to be carefully styled to avoid overlapping text which will break anti-aliasing fonts:
- In some cases a suggestion can cause a line break as the word needs to wrap, but the users currently input text does not cause a wrap, this is especially noticeable with “follow through” typing (typing the characters matching the presented suggestion):
This is resolvable by editing the input value to add newline characters, but this breaks the user’s undo/redo history, and requires a lot of complex state tracking.
- Undo history itself is quite difficult to track, and can frequently disturb the suggestion:
In addition to these various bugs, making an accessible and discoverable interface for suggestions has been challenging.
How we’d like to solve this in the future
Extending the HTMLInputElement and HTMLTextAreaElement interfaces to
include an API to accept and commit suggestions, and have the browser surface
this in a manner cohesive to platform conventions would greatly alleviate the
amount of engineering effort required to present this UI. A proposed sketch for
such an API:
interface SuggestionValueMixin {
undefined suggestValue(DOMString replacementValue);
undefined clearSuggestedValue();
attribute EventHandler onsuggestioncommit;
attribute EventHandler onsuggestiondismiss;
}
HTMLInputElement includes SuggestionValueMixin;
HTMLTextAreaElement includes SuggestionValueMixin;
In addition, it would be useful to have the regions of text that are additions
to the text be selectable via a pseudo-element selector, perhaps ::suggestion
or ::suggestion(n) if multiple regions of suggested text are allowed.
One issue with this API is that suggesting a complete replacement value would mean being able to handle differences such as deletions, which is a far less common UI pattern. Consequently we could look to design an API which inserts only additions at precise locations:
interface Suggestion {
constructor(DOMString insertedValue, int position)
}
interface SuggestionValueMixin {
undefined suggest(Suggestion suggestion);
undefined clearSuggestion(Suggestion suggestion);
attribute EventHandler onsuggestioncommit;
attribute EventHandler onsuggestiondismiss;
}
HTMLInputElement includes SuggestionValueMixin;
HTMLTextAreaElement includes SuggestionValueMixin;
The developer would be expected to know which character position to insert the suggestion, but the upside is that it is much simpler for the developer to anticipate (and for the browser to calculate) where the additions go.
Input Masking
https://github.com/whatwg/html/issues/7794
Input masking is a technique used to separate fragments of a text input into a more recognisable pattern. This makes contiguous strings (such as large numbers or product keys) much easier to read, as they can be formatted to aid in pattern recognition. For example:
- Credit card numbers separated into 4 segements of 4 characters each,
separated by spaces (e.g.
4556 6059 2941 7661). - Separating postal codes with spaces (e.g.
SE1 7PB) - Formatting currencies based on locale, for example using a
,to separate each set of 3 digits (e.g.1 000 000 000). - Formatting dates into a set of two digits for the month & day, and four
digits for the year, divided by slashes or dashes (e.g.
01/01/2025). - Telephone numbers according to the regions locale, which may include dashes,
parenthesis, or spaces (e.g.
(555) 876 5309). - IPv4 addresses into 4 chunks separated by
.s (e.g.192.168.1.1).
Problem Statement
Creating these kinds of masked inputs requires a lot of effort and typically involves combining multiple inputs into one (which can cause issues with copy/paste or deleting inputs), or by injecting characters into inputs (which can cause issues around undo/redo history, and limits the ability to style the masked characters separately from user input).
Many implementations in the wild fail due to usability concerns, or they fail various WCAG critera (some excellent reading material on the topic. Providing a native implementation can alleviate this by creating a simple to use accessible out of the box experience.
How is this solved today?
Many libraries exist to provide this functionality for the web. A non-comprehensive alphabetical list:
Many spreadsheet applications such as Excel provide built-in input masking.
Other languages, platforms and frameworks provide masking as a UI primitive or
have equivalent libraries in their ecosystems, for example .Net’s
maskedtextbox.mask,
or the edittext-mask third party
Android library.
Most libraries expose a microsyntax for expressing the presentational characters of the input, vs the characters the user inputs. The majority (Alpine, inputmask, maska, imask, v-mask, jQuery Mask) define the following characters as special:
9represents an numeric character of the user input (in maska & v-mask this is instead the#symbol).Arepresents an alpha character of the user input (in maska this is instead the@symbol).*represents an alphanumeric character of the user input (in v-mask this is instead theNsymbol).- all other characters represent their respective literal value, as a mask character.
Given the above, this means the following examples will work:
999,999,999is a mask which will allow numeric input, that will add a comma every third digit, so the user inputting123456789will result in the input visually displaying123,456,789.(999) 999-9999is a mask allowing numeric telephone number style input, and will add the(,)and-substrings to the input, thus a user inputting5558765309will result in a rendered input of(555) 876-5309.
How we’d like to solve this in the future
Extending the HTMLInputElement to include a mask attribute that allows
for a microsyntax featuring the A, 9 and * characters seems like a
reasonable step forward. Any literal characters will be filled in as the user’s
input reaches the required length. The ::masked or ::masked(n) pseudo
element selector can be used to select the regions of masked text to style
appropriately. The input’s value will not change, as the masked characters are
presentational only.